

DESCRIPTIVE STATISTICS
DATA HANDLING AND ANALYSIS - PART TWO
A STEP-BY-STEP GUIDE FOR THE COMPLETE BEGINNER
INTRODUCTION TO DESCRIPTIVE STATISTICS
After gathering raw data, it's vital to numerically summarise it for analysis, a process achieved through descriptive statistics. This approach provides a comprehensive view of the data, transforming individual data points, which can be complex and challenging to interpret, into an easier-to-understand format directly.
Descriptive statistics crunch numbers to simplify and summarise data, making it easier to spot overall trends. This includes calculating averages such as the mean, median, or mode to identify the most common values. It also looks at how spread out the data is, using measures like the range, variance, or standard deviation, which helps understand the variability around the average. Choosing the correct statistics depends on the type of data you've got, ensuring a clearer picture. Percentages might also show how much data falls into specific categories or ranges. This approach helps both researchers and readers quickly get the gist of what the data is saying.
However, it's important to note that descriptive statistics only describe the data; they do not assess the probability of the results occurring by chance.
Descriptive statistics play a pivotal role in determining the success of a study. For instance, comparing the mean values across different independent variable (IV) groups can indicate whether there was a significant difference between conditions. However, it's key to remember that descriptive statistics describe the data; they don't evaluate the likelihood that the results happened by chance. So, while descriptive statistics can show if a study did a good job collecting and summarising data, they can't tell us if we should dismiss the hypothesis. Researchers must turn to inferential statistics to determine the chance of seeing the same results again and decide if the hypothesis should be rejected.
Ultimately, descriptive statistics act as a crucial intermediary between raw data and the derivation of actionable insights. They streamline the data analysis and interpretation process, enabling researchers to deduce meaningful conclusions from the dataset.
RAW DATA TO DESCRIPTIVE STATISTICS.
Through a research example, we will explore the transformation of raw data into descriptive statistics and the insights they offer.
BACKGROUND A psychologist investigates the relationship between emotional and physiological states and the activation of the "fight or flight" response. For instance, situations such as fear, stress, sexual arousal, attraction to someone, anger, anxiety, and aerobic exercise can trigger the fight-flight response.
AIM: The psychologist hypothesises that individuals who experience physiological arousal after aerobic exercise will exhibit heightened physical attraction to others.
HYPOTHEIS: "Participants in the jogging condition will rate photographs of the opposite sex higher than participants in the non-jogging condition."
Soon afterwards, the psychologist collects the following raw data:
RAW DATA
*Raw data refers to the unprocessed data collected by the researcher during the study. It has not yet undergone analysis or interpretation.
TABLE 1: RAW DATA
RATINGS OF THE OPPOSITE SEX FROM JOGGERS AND NON-JOGGERS


The raw data consists of attractiveness ratings on a scale from 1 to 10 given by participants to photos of the opposite sex. Before making these ratings, participants were randomly divided into two groups: one that jogged on the spot for ten minutes and another that did not engage in any exercise.
EYEBALL TEST
The "eyeball test" is the initial step researchers undertake upon receiving their raw data, aiming to ascertain the effectiveness of their study. For instance, they examine whether participants in the jogging condition rated photographs of the opposite sex higher than those in the non-jogging condition.
Upon reviewing the raw data in Table 1, the question arises whether it's possible to determine the experiment's success simply by observing the data, such as whether the null hypothesis can be rejected.
The options presented are:
The jogging condition performed better.
The non-jogging condition performed better.
The extensive data makes it impossible to determine which condition performed better.
The expectation is that the third option is the most likely answer, indicating that "It is impossible to determine which condition performed better due to the extensive amount of data." This suggests that the raw data, without further analysis, is not readily interpretable.
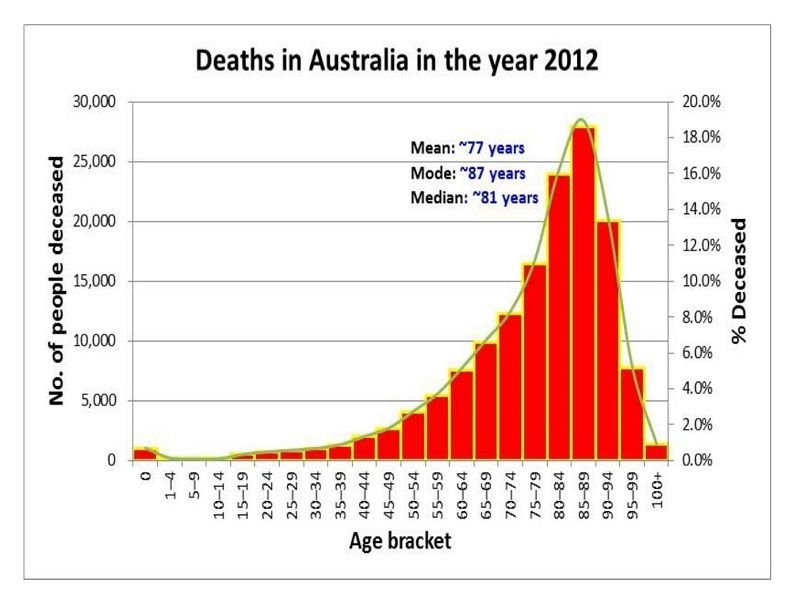
QUESTION: When the central tendency and dispersion measures have been calculated, how do you present the findings?
ANSWER: Researchers present central tendency and dispersion measures in tables or graphs, for example.
Once researchers have calculated measures of central tendency (means, modes, and medians) and dispersion (ranges and standard deviations), they typically present these findings in a structured and visually accessible manner. This is often done through the use of tables and graphs. Tables provide a clear, organized format for displaying numerical data, allowing for easy comparison of the central tendency and dispersion measures across different groups or conditions. Graphs, such as histograms, box plots, or scatter plots, offer a visual representation of the data, highlighting patterns, trends, and outliers. These visual aids help to convey the statistical findings more intuitively, making it easier for both the researchers and their audience to understand and interpret the data's implications.
GRAPH ONE

TABLE TWO: RATINGS OF THE OPPOSITE SEX: JOGGERS V NON-JOGGERS

The data from the experiment has been made interpretable. The primary function of descriptive statistics at this juncture is to help researchers determine the effectiveness of their study or experiment.
Question: Given the information presented in Table 2 and Graph 1, is it appropriate to conclude whether the study has succeeded at this research stage?
DESCRIPTIVE STATISTICS: WHAT YOU NEED TO KNOW
SPECIFICATION:
Descriptive statistics: measures of central tendency – mean, median, mode; calculation of mean, median and mode; measures of dispersion; range and standard deviation; calculation of range; calculation of percentages.
Presentation and display of quantitative data: graphs, tables, scattergrams, bar charts.
Distributions: normal and skewed distributions; characteristics of normal and skewed distributions.
MEASURES OF CENTRAL TENDENCY
Questions such as: “How many miles do I run each day?” or “How much time do I spend on my iPhone each day?” can be hard to answer because the result will vary daily. It’s better to ask, “How many miles do I usually run?” or “On average, how much time do I spend on my iPhone ?”. In this section, we will look at three methods of measuring central tendency: the mean, the median and the mode. Each measure gives us a single value that might be considered typical. Each measure has its strengths and weaknesses.
Measures of central tendency tell us about the most typical value in a data set and are calculated differently. Still, all are concerned with finding a ‘typical’ value from the middle of the data. For any given variable researched, each member of the population will have a particular value of the variable being studied, for example, the number of positive ratings of photographs of the opposite sex. These values are called data. We can apply measures of central tendency to the entire population to get a single value, or we can apply our measures to a subset or sample of the population to get an estimate of the central tendency for the population.
OUTLINE, CALCULATE AND EVALUATE THE USE OF DIFFERENT MEASURES OF CENTRAL TENDENCY:
MEAN
MEDIAN
MODE
This could include saying which one you would use for some data, e.g. 2, 2, 3, 2, 3, 2, 3, 2, 97 - would you use mean or median here?
THE MEAN
Perhaps the most widely used measure of central tendency is the mean. The mean is what people most are referring to when they say ‘average’: it is the arithmetic average of a set of data. It is the most sensitive of all the measures of central tendency as it considers all values in the dataset. Whilst this is a strength as it means that all the data is being considered, the sensitivity of the mean must be considered when deciding which measure of central tendency to use. It can misrepresent the data set if extreme scores are present.
The mean is calculated by adding all the data and dividing the sum by the number of values. The value that is then given should be a value that lies somewhere between the maximum and minimum values of that dataset. If it isn’t, then the calculations have a human error!
For example, an apprentice sits five examinations and gets 94%, 80%, 89%, 88%, and 99%. To calculate their mean score, you would add all the scores together (94+80+89+88+99 = 450) and then divide by the number of scores there are (450÷5 = 90). This gives a mean score of 90%.
ADVANTAGES OF THE MEAN
Sensitive to Precise Data: The mean takes into account every value in the dataset, making it a highly sensitive measure that reflects the nuances of the data.
Mathematically Manageable: It fits nicely into further statistical analyses and mathematical calculations, facilitating various statistical tests.
Widely Used and Understood: As a standard measure of central tendency, most people widely recognise and easily interpret the mean.
DISADVANTAGES OF THE MEAN
Affected by Extreme Values: The mean is sensitive to outliers, which can skew the results and provide a misleading picture of the dataset. Looking at the data set, a mean of 90% looks reasonable, as all scores are close to this value and are between the highest and lowest scores. However, if we now imagine that the apprentice got 17% instead of 94% in their first paper, this completely alters the mean value, and the apprentice’s grade profile drastically decreases! (17+80+89+88+99 = 373 ÷ 5 = 75) This is a mean score of 75%, much lower than four of their other scores; it is an anomaly. Anomalies bias the data.
Not Always Representative: In highly skewed distributions, the mean may not accurately reflect the central location of the data.
Inapplicable to Nominal Data: The mean cannot be calculated for nominal or categorical data, limiting its applicability.
THE MEDIAN
In cases with extreme values in a data set, thus making it difficult to get a true representation of the data by using the mean, the median can be used instead. The median is not affected by extreme scores, so it is ideal when considering a data set that is heavily skewed. It is also easy to calculate, as the median takes the middle value within the data set.
Example: If there are an odd number of scores, then the median is the number which lies directly in the middle when you arrange the scores from lowest to highest. Using the previous data set as an example, five values would be placed in the following order: 12%, 67%, 71%, 72%, and 79%. Therefore, the median value would be the third value, which is 71%.
Interestingly, the median score for this data set is 71%, yet the mean score was 60.2%. It is apparent from the data that the median is a more representative score, which is not distorted by the extreme score of 12%, unlike the mean.
If there is an even number of values within the data set, two values will fall directly in the middle. In this case, the midpoint between these two values is calculated. To do this, the two middle scores are added together and divided by two. This value will then be the median score.
Example: If the above data set included a sixth score, e.g. 12%, 34%, 67%, 71%, 72%, and 79%, then the median score would be 69% (67%+71%÷2).
ADVANTAGES OF THE MEDIAN
Resistant to Outliers: Unlike the mean, the median is not skewed by extreme values, making it a more robust measure in the presence of outliers.
Represents the Middle Value: It accurately reflects the central point of a distribution, especially in skewed datasets, by dividing the dataset into two equal halves.
Applicable to Ordinal Data: The median can be calculated for ordinal data (data that can be ranked) as well as interval and ratio data, offering wider applicability than the mean.
DISADVANTAGES OF THE MEDIAN
Less Sensitive to Data Changes: The median may not reflect small changes in the data, especially if these changes occur away from the middle of the dataset.
Not as Mathematically Handy: It doesn't lend itself as easily to further statistical analysis compared to the mean, due to its non-parametric nature.
Difficult to Handle in Open-Ended Distributions: Calculating the median can be challenging for distributions with open-ended intervals since the exact middle value may not be clear
THE MODE
The third measure of central tendency is the mode. This refers to the value or score most frequently within the data set. While easy to calculate, it can be pretty misleading for the data set. Imagine if the lowest value in the example data set (12%) appeared twice. It wouldn’t represent the whole data set; however, this would be the mode score.
ADVANTAGES OF THE MODE
Versatile with Data Types: The mode is unique because it can be applied to categorical data, which is impossible with the mean and median. For instance, in survey data indicating modes of transportation like 'car', 'bus', or 'walk', the mode identifies the most frequently occurring response, offering valuable insights into the most common category.
DISADVANTAGES OF THE MODE
Potential for Multiple Modes: A dataset can have more than one mode, leading to a bi-modal situation with two modes or even multi-modal with several modes. This can complicate the interpretation of the data.
Possibility of No Mode: In cases where all data points are unique and occur only once, the dataset will have no mode. This lack of a mode can limit the usefulness of the mode as a measure of central tendency in such datasets.
Exam Hint: When asked to calculate any measure of central tendency, show your calculations. Often, the question will be worth two or three marks, so it is important to show how you reached your final answer for maximum marks!

SCENARIO:
You're eyeing an A-level psychology course but have heard negative reviews about one of the teachers at the intended college. Concerned about being assigned to this teacher, you decide to review their latest exam results to gauge the quality of teaching. The data you received is as follows:
Ms. Ainsworth Class Results:

Ms. Ainsworth: class 1
Q. What is the mean for Ms Ainsworth’s psychology class?

Mr. Darwin: class 2
QUESTIONS
What is the mean for Mr Darwin’s psychology class?
Could you determine the superior psychology teacher solely from the average scores at this analysis stage? For instance, how do the outcomes from class 1 and class 2 highlight the drawback of relying only on the mean for evaluation?
What are the ranges for class 1 and class 2?
In what ways does the range provide a more precise depiction of the outcomes from class 1 and class 2?
ANSWERS
First Set of Data:
Mean: The average score for this group is 70/100.
Limitation of the Mean: The mean does not indicate the variability or uniformity in the scores; it only provides the average.
Range: The range is 0, indicating no variability among the scores.
Understanding Data Through Range: The range suggests a uniform performance across the board, but it doesn't highlight individual strengths or weaknesses within the group.
You now get the following data from Mr Pinker’s psychology class:

Mr. Pinker: class 3
Q. What is the range for Mr Pinker’s psychology class?

Dr. Freud: class 4
QUESTIONS
What is the range for Mr. Freued’s psychology class?
Based on the ranges alone, could you choose the best psychology teacher at this point in your analysis, e.g., why do the results from class 3 and class 4 demonstrate a disadvantage of using the range?
What are the means of class 3 and class 4?
How does using the means help describe the results from class 3 and class 4 better?
Which psychology teacher would you choose for your psychology A-Level and why?
ANSWERS
Insight from Combining Measures: Using a measure of central tendency and dispersion provides a fuller understanding of the class's performance dynamics. While the mean shows the average score, the range reveals the spread of scores, highlighting the differences in student achievement levels.
Importance of Dispersion Measures: A sole focus on dispersion, like the range, can sometimes give a misleading picture without the context provided by the mean. However, in this case, it significantly aids in understanding the variability in student performance.
Comparative Analysis: The first class shows uniformity in scoring, suggesting consistent performance or teaching effectiveness. In contrast, the second class's results indicate a wide gap in student performance, suggesting variability in understanding or engagement with the material.
CONCLUSION
Measures of dispersion and central tendency are both really important for reading your data. Knowing whether your study has worked isn't accessible if you do one without the other. While central tendency tells you where most of your data points lie, variability summarizes how far apart your points are from each other. Data sets can have the same central tendency but different levels of variability or vice versa. Together, they give you a complete picture of your data.
MEASURES OF DISPERSION
OUTLINE, CALCULATE AND EVALUATE THE USE OF DIFFERENT MEASURES OF DISPERSION:
RANGE
STANDARD DEVIATION*
CALCULATE PERCENTAGES
*NB You are NOT required to calculate standard deviation; however, they must understand why it is used and what it shows.
THE NORMAL DISTRIBUTION
A normal distribution curve often called a bell curve due to its bell-like shape, is a graphical representation of a statistical distribution where most observations cluster around a central peak—the mean—and taper off symmetrically towards both tails. This curve is characterized by its mean, median, and mode being equal and located at the centre of the distribution.
The reasons it's called "normal" are historical and practical:
Ubiquity in Natural Phenomena: The normal distribution naturally arises in many real-world situations. For example, measurements of height, blood pressure, and test scores in large populations tend to follow this distribution. Because of its common appearance in nature and human activities, it was termed "normal" as if it were the natural state of data. Consider you're exploring the relationship between diet and behaviour, specifically focusing on average daily calorie intake. Typically, you'll find that calorie consumption data is normally distributed, meaning most individuals' intake aligns closely with the mean, while fewer individuals consume significantly more or less than this average.
This insight aligns with logical expectations. It's uncommon for individuals to subsist on a minimal amount like a single serving of cornflakes or, conversely, to consume excessively, such as ten servings of steak and fries daily. Most individuals' consumption levels are moderate, lying near the average.
Central Limit Theorem: This foundational statistical principle states that, under certain conditions, the sum of a large number of random variables, regardless of their distribution, will approximate a normal distribution. This theorem underscores the normal distribution's role in probability and statistics as a central, or "normal," occurrence.
Mathematical Properties: The normal distribution has desirable mathematical properties that simplify analysis. Its mean and standard deviation are fully described, making it a convenient model for statistical inference and hypothesis testing.
In a normal data distribution, most observations are near the "average," with fewer observations at the extremes.
Visualising normally distributed data on a graph would reveal a bell-shaped curve, indicating a concentration of values around the mean and diminishing frequencies towards the extremes.
In summary, the normal distribution is called "normal" not because it is the only or the most morally correct distribution but because of its frequent occurrence and central importance in statistics and natural phenomena.

Not every dataset will produce a graph that fits the ideal shape perfectly. Some may feature curves that are relatively flatter, while others could appear quite sharp. Occasionally, the average might shift slightly to the left or right. However, all data that follow a normal distribution will share the characteristic "bell curve" appearance.
There's a variety of statistical distributions beyond the bell-shaped normal distribution, such as right and left-skewed distributions and bimodal distributions. These terms help to classify common patterns seen in data distribution. For instance, if all 20 psychology students score an A on a mock exam, that would represent a narrow distribution of results. Conversely, if grades span from a U to an A*, the distribution would be much wider. While statistical distributions can get more complex, this overview captures their basic essence.
Results (data) can be "distributed" (spread out) in different ways.

THE NORMAL DISTRIBUTION CURVE

BELL SHAPED
The normal distribution is a pivotal pattern in statistical data distribution, commonly found across a wide range of natural occurrences. It is a specific type of probability distribution where random variations tend to follow a certain predictable pattern, making it the most frequently encountered distribution.
Normal distributions are identifiable by several key traits that become apparent in their graphical representations:
WHAT ARE THE PROPERTIES OF A NORMAL DISTRIBUTION?
Central Tendency Unity: The mean, median, and mode of a normal distribution are identical, congregating at the central peak of the graph.
Described by Mean and Standard Deviation: These two parameters alone can effectively describe the entire normal distribution, with the mean indicating the centre of the distribution and the standard deviation showing the spread of data around the mean.
Symmetry: A hallmark of the normal distribution is its lack of skewness. This means the data is evenly distributed around the central value without leaning towards the left or right.
Bell-shaped Curve: The distinctive symmetrical bell shape of the graph indicates a normal distribution, showcasing most data points gathered around the mean.
Data Concentration: A significant portion of values clusters near the middle of the distribution, illustrating the central tendency's pull.
Equal Distribution Around the Mean: In a perfectly normal distribution, half of the values fall below the mean, while the other half lies above it, reinforcing the distribution's symmetry.
These characteristics make the normal distribution a fundamental statistical concept, underpinning many theoretical and practical applications in various fields.
EXAMPLES OF A NORMAL DISTRIBUTION?
Examples of phenomena that typically exhibit a normal distribution include:
Height of the Population: Height distribution in a given population usually forms a normal curve, with the majority having an average height. The numbers gradually decrease for those significantly taller or shorter than average due to a mix of genetic and environmental factors.
IQ Scores: The distribution of IQ scores across a population also tends to follow a normal distribution. Most individuals' IQs fall within the average range, while fewer people have very high or very low IQs, reflecting various genetic and environmental influences.
Income Distribution: Although not perfectly normal due to various socio-economic factors, income distribution within a country often resembles a normal curve, with a larger middle-class population and fewer individuals at the extreme ends of wealth and poverty.
Shoe Size: The distribution of shoe sizes, particularly within specific gender groups, tends to be normally distributed. This is because the physical attributes that determine shoe size are relatively similar across most of the population, with fewer individuals requiring very large or small sizes.
Birth Weight: The weights of newborns typically follow a normal distribution, with most babies born within a healthy weight range and fewer babies being significantly underweight or overweight at birth.
These examples illustrate how the normal distribution naturally arises in various contexts, providing a useful model for understanding and analyzing data in fields ranging from biology and psychology to economics and social sciences.
RIGHT SKEWED OR POSITIVE DISTRIBUTION.
When a distribution has a few extreme scores toward the low end - relative to the high end or when the opposite is true, for example, It can be spread out more on the LEFT = when this happens, we call it a negative distribution. It can be spread out more on the RIGHT = when this happens, and we call it a positive distribution.

SLOPED TO THE RIGHT
A positive skew is when the long tail is on the positive side of the peak and mean is on the right of the peak value
Some people say it is "skewed to the right".
POSITIVE SKEW
The positively skewed distribution is a distribution where the mean, median, and mode are positive rather than negative or zero, i.e., data distribution occurs more on the one side of the scale with a long tail on the right side. It is also known as the right-skewed distribution, where the mean is generally to the right side of the data median.
Positive (right-skewed) distributions occur when the data's tail is longer towards the right-hand side of the distribution. This usually means a few high values are stretching the scale of the graph to the right while most of the data clusters towards the lower end. Here are examples of positive distributions and explanations for why they exhibit right-skewness:
EXAMPLES OF POSITIVE DISTRIBUTIONS AND EXPLANATIONS
Individual Incomes: The distribution of individual incomes is right-skewed, as most people earn within a certain range, but a notable minority earn significantly more, extending the distribution's tail to the right.
Scores on Difficult Exams: For challenging exams, most scores are low to moderate, with a few exceptional scores pulling the distribution's tail to the right, indicating a positive skew.
Number of Pets per Household: Most households have zero or one pet, but a few households with a large number of pets (e.g., seven or more) create outliers that skew the distribution positively.
Movie Ticket Sales: While the ticket sales for many movies are relatively low, blockbuster hits that sell millions of tickets cause a rightward skew in the overall distribution of movie ticket sales.
Mileage on Used Cars for Sale: The mileage distribution for used cars is positively skewed; most have lower mileage, but cars with very high mileage create a long tail to the right.
Reaction Times in a Psychology Experiment: In experiments measuring reaction times, the distribution is positively skewed by individuals with slower reaction times, even as most participants show faster responses.
House Prices: The distribution of house prices shows a positive skew because while most homes are moderately priced, a few exceptionally high-priced luxury homes extend the tail to the right.
Number of Accident Claims by an Insurance Customer: Insurance claim numbers are typically low for most customers, but a small percentage filing multiple claims leads to a right-skewed distribution.
Number of Children in a Family: Family size tends to be small, with one or two children being familiar, but families with many children create outliers that result in a positively skewed distribution.
These examples demonstrate positive distributions where the bulk of data points cluster at the lower end of the scale, but significant outliers on the higher end cause the distribution to skew right. This skewness reflects rare but extreme values stretching the distribution's tail towards the higher values.
LEFT SKEWED OR NEGATIVE DISTRIBUTION

SLOPED TO THE LEFT
Why is it called negative skew? Because the long "tail" is on the negative side of the peak and the mean is on the left of the peak.
Some people say it is "skewed to the left" (the long tail is on the left hand side)
NEGATIVE SKEW
The negatively skewed distribution is a distribution where the mean, median, and mode of the distribution are negative rather than positive. i.e., data distribution occurs more on the one side of the scale with a long tail on the left side. It is also known as the left-skewed distribution, where the mean is generally to the left side of the data median.
EXAMPLES OF NEGATIVE DISTRIBUTIONS AND EXPLANATIONS
Olympic Long Jump Lengths: In Olympic competitions, most athletes' long jumps cluster around 7.5-8 meters, with a few jumps at the lower range of 5-6 meters, creating a negatively skewed distribution because the outliers are on the lower end.
Scores on Easy Exams: For exams that are not challenging, scores generally hover near the top end, with a minority of students scoring lower. This scenario results in a negative skew as most data is concentrated on the higher scores with fewer low scores.
Age at Retirement: The typical retirement age sees the bulk of retirements. However, a segment retiring significantly earlier skews the distribution leftward, with the early retirees acting as the lower-end outliers.
Time to Complete a Task: When analyzing task completion times, if a majority take a longer time but a few finish exceptionally quickly, this results in a negatively skewed distribution. The quick completions are the outliers that pull the distribution's tail to the left.
The durability of Consumer Products: With most products lasting up to or just beyond their expected lifespan and a few failing prematurely, the early failures create a left skew in the distribution, highlighting most products that last longer.
Life Span of High-Tech Devices: Although most high-tech gadgets last long, the few that break down early cause the distribution to skew negatively, emphasizing the longer-lasting majority.
Age of Death: The distribution of the age of death in most populations is negatively skewed as most people die in old age.
Damage Claims After Minor Natural Disasters: When most properties incur no or minimal damage (considered higher values), and a few experiences more severe damage, the distribution skews left, with severe damages rare.
Books Read per Year by Individuals: If most people read a few books but a select few read extensively, the distribution of the number of books read skews negatively, emphasizing the commonality of reading fewer books.
Prepayment of Loans: The tendency for most to adhere to the regular payment schedule, with a few paying off their loans early, results in a negatively skewed distribution, showcasing the rarity of early loan settlement.
These examples illustrate negative distributions where most data points are located towards the higher end of the scale. However, a few significant outliers on the lower end cause the distribution to skew left.
NO DISTRIBUTION
No distribution means the data does not follow a known distribution pattern or that the distribution cannot be identified or specified.
NO DISCERNIBLE SHAPE
Sometimes the results have no pattern
MEASURES OF DISPERSION
The measures of dispersion you use in statistics show you the spread/variability of the raw data results. The three main types are the range, the inter-quartile range and the standard deviation
In statistics, measures of dispersion are crucial for illustrating the spread or variability of raw data results. The three primary types are the range, the interquartile range, and the standard deviation.
THE RANGE
The range is the most straightforward measure of dispersion. It is determined by only two values in a dataset: the highest and the lowest. Additionally, the range is easy to calculate.
CALCULATION OF THE RANGE
The range is calculated by subtracting the lowest score in the dataset from the highest score and (usually) adding 1. This addition of 1 is a mathematical correction to account for any rounding up or down that may have occurred in the dataset's scores.
EVALUATION
Strengths:
The range is straightforward to calculate, offering a clear advantage in its simplicity.
Weaknesses:
It only considers the two extreme scores, the highest and the lowest, which may not accurately represent the dataset as a whole.
It's crucial to acknowledge that the range may be the same in datasets with a strong negative skew (e.g., most students scoring well on a psychology test) and those with a strong positive skew (e.g., most students scoring poorly on a psychology test), highlighting a limitation in its ability to distinguish between differently skewed datasets.
To effectively evaluate the range as a measure of dispersion, consider applying it to the provided datasets below.
EXAMPLE A
The lowest value Is 0 and the highest is 100 which means the range is 1 (100 - 0)+1=1) or (100 - 0) = 0

EXAMPLE B
The lowest value Is 0 and the highest is 100 which means the range is 1 (100 - 0)+1=1) or (100 - 0) = 0
THE INTER QUARTILE RANGE
An inter-quartile range is the difference between the upper and lower quartiles in a set of ordered scores. Quartiles are formed by dividing a set of ordered scores into four equal-sized groups.

t
THE STANDARD DEVIATION
I'll be honest. Standard deviation is a more complex concept than the range.
Standard deviation stands out as a more intricate measure than the range, yet it's incredibly insightful in deeply understanding data.
Regarded as the pinnacle among descriptive statistics, standard deviation could be considered the "mean of the mean." Without it, the full narrative woven by the data remains elusive.
Standard deviation is a crucial measure in statistics and probability theory, capturing the extent of variability or diversity from the average or mean. Essentially, it quantifies the spread of results.
Standard deviation is like a measuring tape for how spread out numbers are in a data set. Imagine you have many points on a line: if they're all huddled close together, there's not much difference between them, so the standard deviation is small. But if they're all over the place, far from each other, then the standard deviation is large because there's a lot of variety in the numbers. It's a way to see how much things differ from the average or the "normal" amount. So, if everyone in your class scores similarly on a test, the standard deviation will be low. But if scores are all over the map, the standard deviation will be high, showing a big range in how everyone did.
For example, when the results are clustered around the mean and tightly grouped, the bell-shaped curve will be steep, and the standard deviation will be small. But when the results are spread far apart, the bell curve is relatively flat; the standard deviation is large. For example, a small standard deviation could be 20/20 students scoring A* on a test, and a large standard deviation could be 20 students scoring between A* on a test.

FOR EXAMPLE
A small standard deviation could be 50/50 music students getting a merit in a music exam
A large standard deviation could be 50 music students getting varying results from failure to distinction.
THE SIZE OF THE STANDARD DEVIATION MATTERS


100% OF THE POPULATION
Note the bell shaped curve and the symmetry.

THE 3 STANDARD DEVIATION LINES
Note the three standard deviation lines: 123
They are replicated on each side.
These are your markers for not only the spread of data - e.g., how far out of the norm is the behaviour being measured? For example, having 12 meals per day would not be a norm, so you would not find this result clustered around the mean.
Secondly, standard deviations tell you the percentage of people at each level of dispersion. With the range, this is not possible, so if results in Class A are 0-100, we don’t know if one person scored 100% or 99% of students did. But with the standard deviation, we do know because it calculates the percentage of people at each stage of the dispersion.
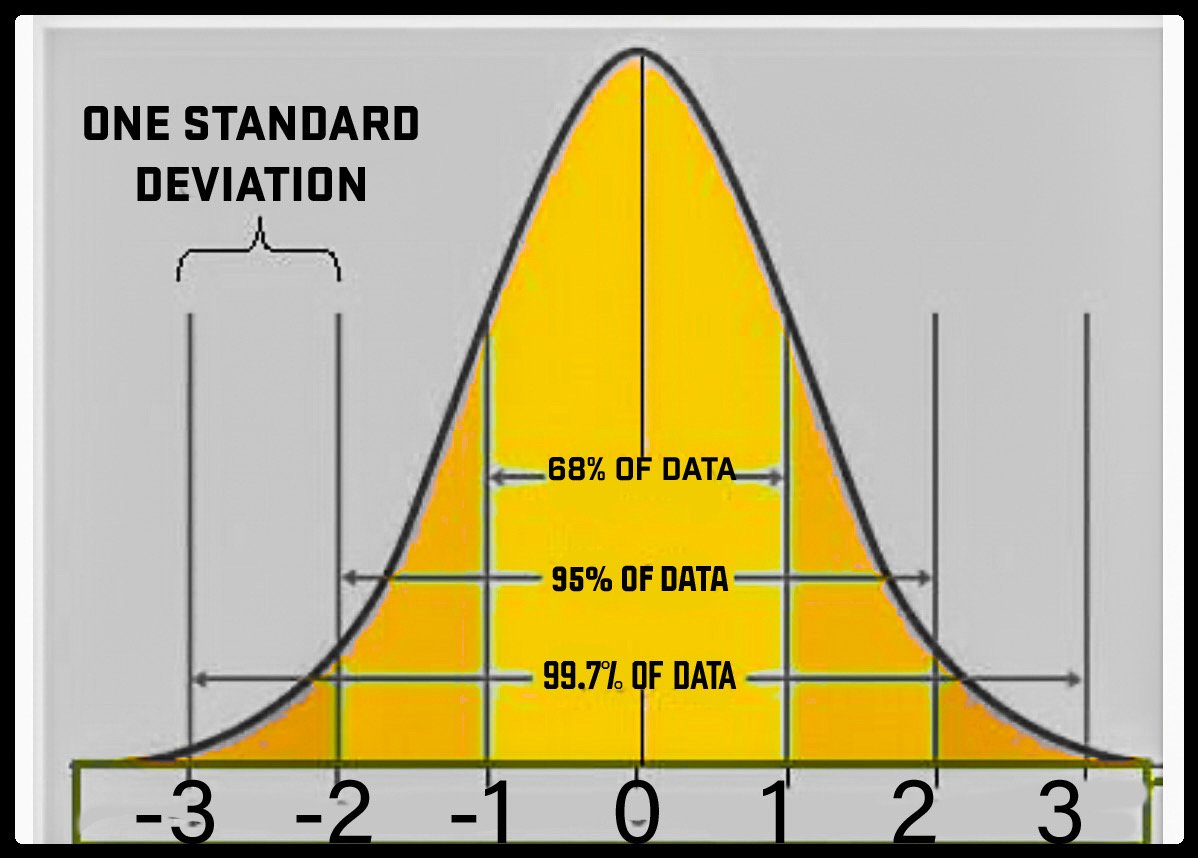
The standard deviation is a measure of how spread out numbers are.
When we calculate the standard deviation, we find that generally:
One Standard Deviation from the mean is 68% of the population
Two Standard Deviations from the mean is 95% of the population
Three Standard Deviations from the mean is 99.7% of the population
68% of the population are within 1 standard deviation from the mean

One standard deviation away from the mean in either direction on the horizontal axis (the two shaded areas closest to the center axis on the above graph) accounts for somewhere around 68 percent of the people in this group.
95% of the population are 2 standard deviation from the mean

Two standard deviations away from the mean (the four areas closest to the center areas) account for roughly 95 percent of the people.
99.7% of the population are within 3 standard deviation from the mean

And three standard deviations (all the shaded areas) account for about 99 percent of the people.
It is good to know the standard deviation because we can say that any value is:
One standard deviation is 68 out of 100
Two standard deviation is 95 out of 100
Three standard deviations 99.7 out of 100
THE STANDARD DEVIATION OF IQ

WHAT IQ TEST SCORES MEAN
145 and above - genius, e.g., Einstein 160, Marilyn-Vos-Savant: IQ 228, Ainan Cawley: IQ 263
145-130 and above- very superior, inventor, scientist = 2.1%
121-130 -superior - 125 is the mean of persons receiving a Ph.D. and M.D. degrees= 6.4%
111-120 - high average - 111 is the mean of an A-level student = 15.7%
90-110 - 100 is the average for the total population, 51.6%
80-89 - Low average = 13.7%
70-79 - borderline - at 75, there is about a 50-50 chance of reaching year 9 = 6.4%
Scores under 70 - extremely low - profound learning difficulties; for example, Down syndrome is between 30-70
Scores 30 - people with Profound and Multiple Learning Difficulties have a severe intellectual disability (an IQ of less than 20), often combined with other significant problems and complex needs. These may include physical disabilities, sensory impairment and severe medical needs.
CALCULATION
To clarify: It's stated that 99% of people have an IQ range from 55 to 145.
Given the assumption of a normal distribution, we aim to find the mean and standard deviation.
The mean is the midpoint of 55 and 145, calculated as:
Mean = (55 + 145) / 2 = 100
Considering 99% of the data falls within three standard deviations from the mean (spanning six standard deviations in total):
One standard deviation is calculated by dividing the range (145 - 55) by 6
Standard Deviation = (145 - 55) / 6 = 90 / 6 = 15
IQ STATISTICS
68% of the population have an IQ between 85-115
95% of the population have an IQ between 70-130
99.7% of the population have an IQ between 55-145

1 STANDARD DEVIATION FROM THE MEAN
68% of people have an IQ between 85 and 115

2 STANDARD DEVIATIONS FROM THE MEAN
95 % of people have an IQ between 70 and 130

3 STANDARD DEVIATIONS FROM THE MEAN
99.7% of people have an IQ between 55 and 145

1 + Standard deviation from the mean.
68% of the population have an IQ of between 85-115. However, the right side of the standard deviation represents half of the population, which is 34.13%. This means that 34% of people have an IQ between 100-115.
2+ Standard deviation from the mean.
95% of the population have an IQ of between 70-130. However, the right side of the standard deviation represents half of the population, which is 47.5%.
47.5 - 34.13 = 13.59
This means that 13.58% of people have an IQ between 115-130.
3 + Standard deviation from the mean.
99.7% of the population have an IQ of between 55-145. However, the right side of the standard deviation represents half of the population, which is 49.85%.
49.85 - 34.13 - 13.59 = 2.14
This means that 2.14% of people have an IQ between 130-145.
49.85 - 34.13 - 13.59 - 2.14 = 0.13% of people have an IQ above 145.

.1 - Standard deviation from the mean.
68% of the population have an IQ of between 85-100. However, the right side of the standard deviation represents half of the population, which is 34.13%. This means that 34% of people have an IQ between 100-85.
2- Standard deviation from the mean.
95% of the population have an IQ of between 85-70. However, the right side of the standard deviation represents half of the population, which is 47.5%.
47.5 - 34.13 = 13.59
This means that 13.58% of people have an IQ between 85-70.
3 - Standard deviation from the mean.
99.7% of the population have an IQ of between 70-55. However, the right side of the standard deviation represents half of the population, which is 49.85%.
49.85 - 34.13 - 13.59 = 2.14
This means that 2.14% of people have an IQ between 70-55.
49.85 - 34.13 - 13.59 - 2.14 = 0.13% of people have an IQ below 55.
APPLIED EXAMPLE: COMPARING SLIMMER'S WORLD AND WEIGHT WATCHER DIETS
THE UTILITY OF STANDARD DEVIATIONS: Standard deviations can be crucial in understanding the variability of weight loss results among individuals following different diets, revealing the range of outcomes within each diet program.
Imagine the following scenario:
“You're looking to shed some pounds and have learned that being part of a support group, like Weight Watchers or Slimming World, boosts your odds of success. But are you faced with the choice, which one do you pick? Naturally, you aim to join the group with the most impressive outcomes. Embracing your inner nerd, you request descriptive statistics to verify their success stories and receive weight loss data for 5,000 dieters.”

OPTION 1: *SLIMMING WORLD
Pounds in weight lost during 06/21 - 08/21
SD = 8
MEAN = 20.

OPTION 2: *WEIGHT WATCHERS
Pounds in weight lost during 06/21 - 0821
SD = 2
MEAN = 10
*Disclaimer: Please be aware that the data provided above is entirely fictional, and I possess no knowledge of the actual performance, success, or failure rates of Weight Watchers or Slimming World. Nonetheless, it's worth noting that participating in a support group is generally advantageous.
QUESTIONS:
Which diet did you choose and why?
Why do you think the slimming world had such a big SD, but Weight Watchers didn’t?
POSSIBLE DISCUSSION POINTS
Which diet did you opt for, and what were your reasons?
What are your thoughts on why Slimming World exhibited a large standard deviation while Weight Watchers did not?
You may have selected the Weight Watchers program, emphasising the predictability and consistency in weight loss it offers its participants. The fact that 99% of individuals following Weight Watchers experienced a weight loss ranging from 4 to 16 pounds over three months proves its reliability. In contrast, those on the Slimming World plan experienced a broader spectrum of results, including losses of up to 44 pounds, which is notable, but also instances where individuals gained up to 4 pounds, which could be seen as less favourable.
At first glance, Slimming World might be less effective than Weight Watchers. Yet, a deeper exploration might uncover specific reasons behind these varied outcomes. For example, the average results for Slimming World could have been skewed by the presence of lifetime members who have plateaued in their weight loss journey. This factor, or the possibility that Slimming World's program might be perceived as more complex or too restrictive, could account for its wide range of results.
Alternatively, the perceived efficacy of the Weight Watchers diet could stem from its clear guidelines, diverse food choices, and robust support system provided by group leaders. The notable success among Weight Watchers participants could also be linked to the expertise of a highly experienced group leader.
These considerations highlight the importance of looking beyond surface-level data to understand the factors that contribute to the success or limitations of a weight loss program, underscoring the nuanced nature of dietary effectiveness and participant experience.

AQA EXAM QUESTION: STANDARD DEVIATIONS
A psychologist believed that people think of more new ideas working on their own than working in a group and that the belief that people are more creative in groups is false. To test this idea, he arranged for 30 people to participate in a study that involved generating ideas about how to boost tourism. Participants were randomly allocated to one of two groups. Fifteen of them were asked to work individually and generate as many ideas as possible to boost tourism in their town. The other fifteen participants were divided into three groups, and each group was asked to "brainstorm" to generate as many ideas as possible to boost tourism in their town. The group "brainstorming” sessions were recorded, and the number of ideas generated by each participant was noted. The psychologist used a statistical test to determine if there was a significant difference in the number of ideas generated by the participants working alone compared to the number of ideas generated by the participants working in groups. A significant difference was found at the 5% level for a two-tailed test (p ≤ 0.05).”
TABLE 3: MEAN NUMBER OF IDEAS GENERATED WHEN WORKING ALONE AND WHEN WORKING IN A GROUP

QUESTION: Concerning the data in Table 3, outline and discuss the findings of this investigation. (10 marks)AO1 = 3-4 marks and AO2/3 = six marks:
Exam hint: Questions regarding the interpretation of standard deviation values are often worth several marks, so linking your answer to the question rather than just pointing out how they differ is essential. Tell the examiner what these scores tell you about the data!
ESSAY ADVICE
AO1 = 3-4 marks: Outline the findings of the investigation
STEP 1: Look carefully at the descriptive statistics: Think about what the difference between the two MEANS tells us.
STEP 2: Work out the standard deviations for both conditions. Remember, you only need two numbers: the MEAN and the SD. Incrementally increase the mean by the standard deviation (SD) three times towards the right. Similarly, decrease the mean by the SD three times towards the left, each time progressively.
FOR EXAMPLE:
WORKING-ALONE-CONDITION

GRAPH A: MEAN NUMBER OF IDEAS GENERATED WHEN WHEN WORKING ALONE
THE STANDARD DEVIATION = 1
THE MEAN = 14
RIGHT-SIDE OF THE STANDARD DEVIATION
14 + 1 = 15 for 1 SD to the right
15 + 1 = 16 for 2 SD to the right
16 + 1 = 17 for 3 SD to the right
LEFT SIDE OF THE STANDARD DEVIATION
14 - 1 = 13 for 1 SD to the left
13 - 1 = 12 for 2 SD to the left
12 - 1 = 11 for3 SD to the left
THIS MEANS:
1 standard deviation or 68% of the population scored between 13 - 15 ideas on how to boost tourism
2 standard deviations or 65% of this population scored between 12 - 16 ideas on how to boost tourism
3 standard deviations or 99% of this population, scored between 11 - 17 ideas on how to boost tourism
WORKING-IN-A-GROUP-CONDITION

GRAPH B: MEAN NUMBER OF IDEAS GENERATED WHEN WHEN WORKING IN A GROUP
THE STANDARD DEVIATION = 2.2
THE MEAN = 8
RIGHT-SIDE OF THE STANDARD DEVIATION
8 + 2.2 = 10.2 for 1 SD to the right
10.2 + 2.2 = 12.4 for 2 SD to the right
12.4 + 2.2 = 14. 6 for 3 SD to the right
LEFT SIDE OF THE STANDARD DEVIATION
8 - 2.2 = 5.8 for 1 SD to the left
5.8 - 2.2 = 3.5 for 2 SD to the left
3.5 - 2.2 = 1.3 for 3 SD to the left
THIS MEANS:
One standard deviation or 68% of this population. I scored between 5.8 and 10.2 on ideas on how to boost tourism
Two standard deviations, or 65% of this population, scored between 3.5 and 12.4 ideas on how to boost tourism
Three standard deviations, or 99% of this population, scored between 1.3 and 14.6 ideas on how to boost tourism
STEP 3: AO2/3 = six marks: Analysis, evaluation and interpretation of other's methodology and the impact of findings.
Numerous approaches can be taken to explore and discuss this question.
The essay should begin by summarising the findings, such as what the mean suggests: a significant insight, for instance, is that individuals working alone produced almost twice as many ideas as those in groups. This should lead to examining the mean's implications and what it may not reveal. The discussion then advances to the importance of the standard deviation, which provides additional details absent from the mean. It highlights discoveries and their importance, like one group's results being significantly smaller than another's. A critical examination of the standard deviation's size and what it indicates about the study's validity and reliability, especially regarding internal validity, follows.
The critique must be rooted in the specifics presented in the essay question, clarifying why the standard deviations for solo participants versus those in groups varied so markedly.
A key point to understand is that a larger standard deviation implies reduced validity and reliability of findings.
The analysis should investigate the reasons behind the increased variability observed among group participants. Considering the wide range of scores among group participants (from 1.3 to 14-6) compared to the more uniform scores in the solo condition (with 99% of participants generating 11-17 ideas on tourism), it's important to speculate on the possible methodological or contextual factors involved.
This variability could either affirm the experiment's hypothesis, suggesting a higher level of creativity when working alone, or it could point to potential flaws in the experiment's design or execution, thus questioning its internal validity. Identifying and discussing the potential causes for the differences in standard deviations and means across the two scenarios is crucial.
Questions should be raised about why the mean was greater for individuals working alone, accompanied by a smaller standard deviation than those in a group setting. The significance of these results, their potential implications for the experiment's methodology, and the reliability of the group condition's outcomes deserve thorough exploration.
This analysis underscores the critical roles of variation and reliability in the scientific method and their relevance in everyday life, showcasing how these scientific principles are in research and everyday decision-making.
ANSWER TO THE GENERATING IDEAS QUESTION
“In the "working alone" condition, the mean was 14, nearly double the mean of 8 observed in the "working in a group" condition. This indicates that participants working alone produced significantly more ideas for generating tourism. However, means alone do not account for outliers - it's conceivable that a few high-scoring individuals in the solo condition elevated the mean or that particularly low scores in one group depressed it.
The standard deviation (SD) provides a more nuanced understanding by measuring variation from the mean. The SD in the "working alone" condition was 1.2, less than that in the "working in a group" condition, suggesting a tighter clustering of scores around the mean. A smaller SD indicates more uniformity among participants' responses, lending credence to the influence of the independent variable on the dependent variable.
Specifically, 68% of individuals working alone scored 13 to 15 ideas, while 68% of those in the group condition produced ideas ranging from 5.8 to 10.2. Such a disparity in SDs typically implies that one group's findings, such as those working alone, might be more reliable due to less variability in their scores. The larger SD in the group condition hints at lower reliability, possibly due to greater score variance. This could point to issues in experimental design or suggest that individual creativity is indeed higher when working alone.
The broader variance in the group condition's scores could stem from diverse group dynamics, making group outcomes less predictable. For instance, shy individuals might not contribute as much in a group, whereas they could freely generate ideas alone. Conversely, some groups might be dominated by a single member, skewing the results.
A significant oversight was the lack of clear operationalization of what constitutes an "idea," leading to variability in what was considered valid. This inconsistency could have affected the results, with some groups prioritizing idea quality over quantity, thereby spending more time evaluating each suggestion. The methodology could have been more precise in guiding participant responses. Using nominal data to calculate standard deviation may not have been appropriate. Moreover, the sheer volume of ideas generated as a measure of creativity is questionable; groups generating fewer ideas might have offered more innovative or quality suggestions, challenging the validity of the dependent variable as a true measure of creativity.”
CALCULATION OF PERCENTAGES
Providing percentages in the summary of a dataset can help the reader get a feel for the data at a glance without needing to read all of the results. For example, if two conditions compare the effects of revision vs. no revision on test scores, a psychologist could provide the percentage of participants who performed better after revising to give a rough idea of the study's findings. Let’s imagine that out of 45 participants, 37 improved their scores by revising.
To calculate a percentage, the following calculation would be used:
Number of participants who improved × 100 Total number of participants
The bottom number in the formula should always be the total number in question (such as the total number of participants or the total possible score), with the top number being the number that meets the specific criteria (such as participants who improved or a particular score achieved). This answer is then multiplied by 100 to provide the percentage.
CALCULATION OF PERCENTAGE INCREASE
First, the difference, i.e. increase, between the two numbers being compared must be calculated to calculate a percentage increase. Then, the increase should be divided by the original figure and multiplied by 100 (see example calculation below).
For example, A researcher was interested in investigating the effect of listening to music on the time to read a text passage. When participants were asked to read with music playing in the background, the average time to complete the activity was 90 seconds. When participants undertook the activity without music, the average time to complete the reading was 68 seconds.
Calculate the percentage increase in the average (mean) time to read a text passage when listening to music. Show your calculations. (4 marks)
Increase = new number – original number Increase = 90 – 68 = 22
% increase = increase ÷ original number × 100 % increase = 22 ÷ 68 × 100
22/78 = 0.3235
0.3235 × 100 = 32.35%
CALCULATION OF PERCENTAGE DECREASE
First, the decrease between the two compared numbers must be calculated to calculate a percentage decrease. Then, the decrease should be divided by the original figure and multiplied by 100 (see example calculation below).
For example, A researcher was interested in investigating the effect of chewing gum on the time taken to tie shoelaces. When participants were asked to tie a pair of shoelaces in trainers whilst chewing a piece of gum, the average time to complete the activity was 20 seconds. When participants undertook the activity without chewing gum, the average time to tie the shoelaces was 17 seconds.
Calculate the percentage decrease in the average (mean) time taken to tie shoelaces when not chewing gum. Show your calculations. (4 marks)
Decrease = original number – new number Decrease = 20 – 17 = 3
% decrease = decrease ÷ original number × 100 % decrease = 3 ÷ 20 × 100
3/20 = 0.15
0.15 × 100 = 15%
POSSIBLE EXAMINATION QUESTIONS
Name one measure of central tendency. (1 mark)
Exam Hint: As this question asks for a measure of central tendency to be named, no further elaboration is required to gain the mark here.
Which of the following is a measure of dispersion? (1 mark)
Mean
Median
Mode
Range
Calculate the mode for the following data set: 10,2,7,6,9,10,11,13,12,6,28,10. (1 mark)
Calculate the mean from the following data set. Show your workings: 4, 2, 8, 10, 5, 9, 11, 15, 4, 16, 20 (2 marks)
Explain the meaning of standard deviation as a measure of dispersion. (2 marks)
Other than the mean, name one measure of central tendency and explain how you would apply this to a data set. (3 marks)
Exam Hint: It is vitally important that time is taken to read the question fully to ensure that a description of calculating the mean is also presented.
Explain why the mode is sometimes a more appropriate measure of central tendency than the mean. (3 marks)
Explain one strength and one limitation of the range as a measure of dispersion. (4 marks)
Evaluate the use of the mean as a measure of central tendency. You may refer to strengths and limitations in your response. (4 marks)
A researcher was interested in investigating the number of minor errors that both male and female learner drivers made on their driving test. Ten males and ten females agreed for the performance on their driving test to be submitted to the researchers. The table below depicts the findings:
PRESENTATION AND DISPLAY OF QUANTITATIVE DATA: GRAPHS, TABLES, SCATTERGRAMS, BAR CHARTS.
If you don’t understand what levels of measurement are, e.g., how different types of data get categorized into the following groups: Nominal, ordinal, Interval, and Ratio, then click here to learn about them.

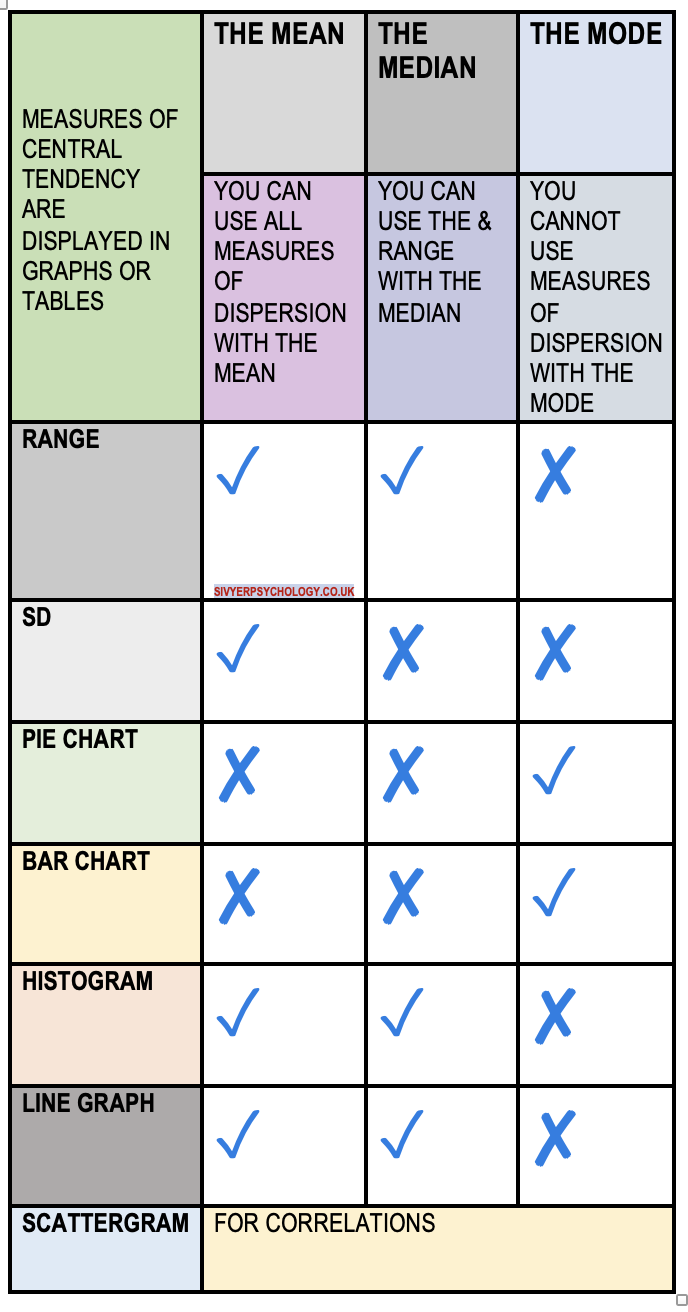
PIE CHART
Pie charts are ideal for illustrating how different segments make up a whole. They are not suitable for displaying trends or changes over time.
Data Type: Discrete quantitative
Measurement Level: Nominal
Measures of Dispersion: Not applicable
Central Tendency Measure: Mode

BAR GRAPH
Bar graphs excel at contrasting quantities across various groups.
These graphs feature spaces between bars to signify the discrete nature of the data values.
Data Type: Discrete quantitative
Measurement Level: Nominal
Measures of Dispersion: Not applicable
Central Tendency Measure: Mode

HISTOGRAMS AND BAR CHARTS DIFFERENCES

HISTOGRAM
A histogram uses vertical bars to display frequency distributions, such as the occurrence frequency of various scores. It consists of two axes: the x-axis (horizontal), typically representing time intervals or categories, and the y-axis (vertical), indicating the quantity or frequency of what is being measured.
Unlike bar graphs, histograms lack gaps between bars, reflecting the continuous nature of the data.
Data Type: Quantitative-continuous
Measurement Level: Ordinal, Interval, Ratio
Measures of Dispersion: For interval and ratio data, standard deviation, range, and interquartile range are applicable.
Central Tendency Measures: Mean (for interval and ratio data), mode, and median.

LINE GRAPH
Line graphs illustrate changes or trends over time, featuring a horizontal x-axis, typically denoting the period, and a vertical y-axis, representing the measured variable.
Data Type: Quantitative-continuous
Measurement Level: Ordinal, Interval, Ratio
Measures of Dispersion: For data at the interval level and above, applicable measures include standard deviation, range, and interquartile range.
Central Tendency Measures: Mean (for interval and ratio data), in addition to mode and median.

SCATTERGRAPH
The scattergram, exclusively utilized for correlational studies, visually represents the relationship between two continuous quantitative variables. This graph consists of points, often marked as crosses, plotted to indicate the association between variables along the horizontal and vertical axes.
In correlational analysis, the choice of graph is limited to the scattergram.
The placement of variables on the x and y axes is flexible.
Data Type: Quantitative-continuous
Measurement Level: Ordinal, Interval, Ratio
Measures of Dispersion: Applicable for interval and higher levels of data, including standard deviation, range, and interquartile range.
Central Tendency Measures: Mean (for interval and ratio levels), mode, and median.

CONTINGENCY TABLE
Contingency tables are employed to analyse the frequency counts of subjects across different categories to assess the potential association between variables.
Data Type: Discrete quantitative
Measurement Level: Nominal
Measures of Dispersion: Not applicable
Central Tendency Measures: Mode and frequencies

CONTINGENCY TABLES TO DISPLAY MEASURES OF CENTRAL TENDENCY AND DISPERSION
To display numerical forms of measures of central tendency and dispersion
USEFUL SUMMARY

For categorical (nominal) data, your options for graphical representation are limited to pie charts or bar charts, and the only measure of central tendency applicable is the mode. Measures of dispersion cannot be applied to nominal data, but such data can be organised into contingency tables.
With ordinal data, the appropriate measures of central tendency are the mode and median. Graphically, this type of data is best represented through histograms or line graphs. However, measures of dispersion are not suitable for ordinal data.
For interval data, you can employ the mode, median, and mean as measures of central tendency. The graphical representation of interval data can be effectively achieved through line graphs or histograms, and employing measures of dispersion is appropriate and valuable.
You can utilise the full spectrum of statistical measures for ratio data, including all interval data properties and a true zero point. This means you can apply the mode, median, and mean to describe the central tendency of the data. Graphically, ratio data can be represented through various charts, including histograms, line graphs, and scatter plots, depending on the nature of the data and the analysis objective.
Additionally, ratio data allows for using all measures of dispersion, such as range, variance, and standard deviation, to describe the spread or variability within the data set. This comprehensive suite of statistical tools is due to the meaningful nature of the zero point in ratio data, which allows for comparisons of absolute magnitudes.